How we collected 10,000 hours of neuro-language data in our basement
What we learned about operations and ML from running data collection 20 hours a day
Over the last 6 months, we collected ~10k hours of data across thousands of unique individuals. As far as we know, this is the largest neuro-language dataset in the world.[1]See here, here, here, here, and here (discussion only, no data available) for some of the larger datasets. See recent papers discussing the problem of small datasets here, here, and here. Why did we do this? We train thought-to-text models. That is, we train models to decode semantic content from noninvasive neural data. Here are some entirely zero-shot examples:
| Ground truth | Model prediction (based ONLY on neural data)[2] |
|---|---|
| the room seemed colder | there was a breeze even a gentle gust |
| do you have a favorite app or website | do you have any favorite robot |
| then she smiled faintly and nodded | she shrugged, hoping to look indifferent. |
| All examples are zero-shot to new subjects, whom the model has never seen before. | |
We'll write about the model in a future post. But before you can train a model that generalizes to new people, you need to get many thousands of hours of data. When we started, the existing datasets were either inapplicable or tiny. Most were in the low hundreds of hours (if that), and most had tens or, at a stretch, hundreds of subjects.
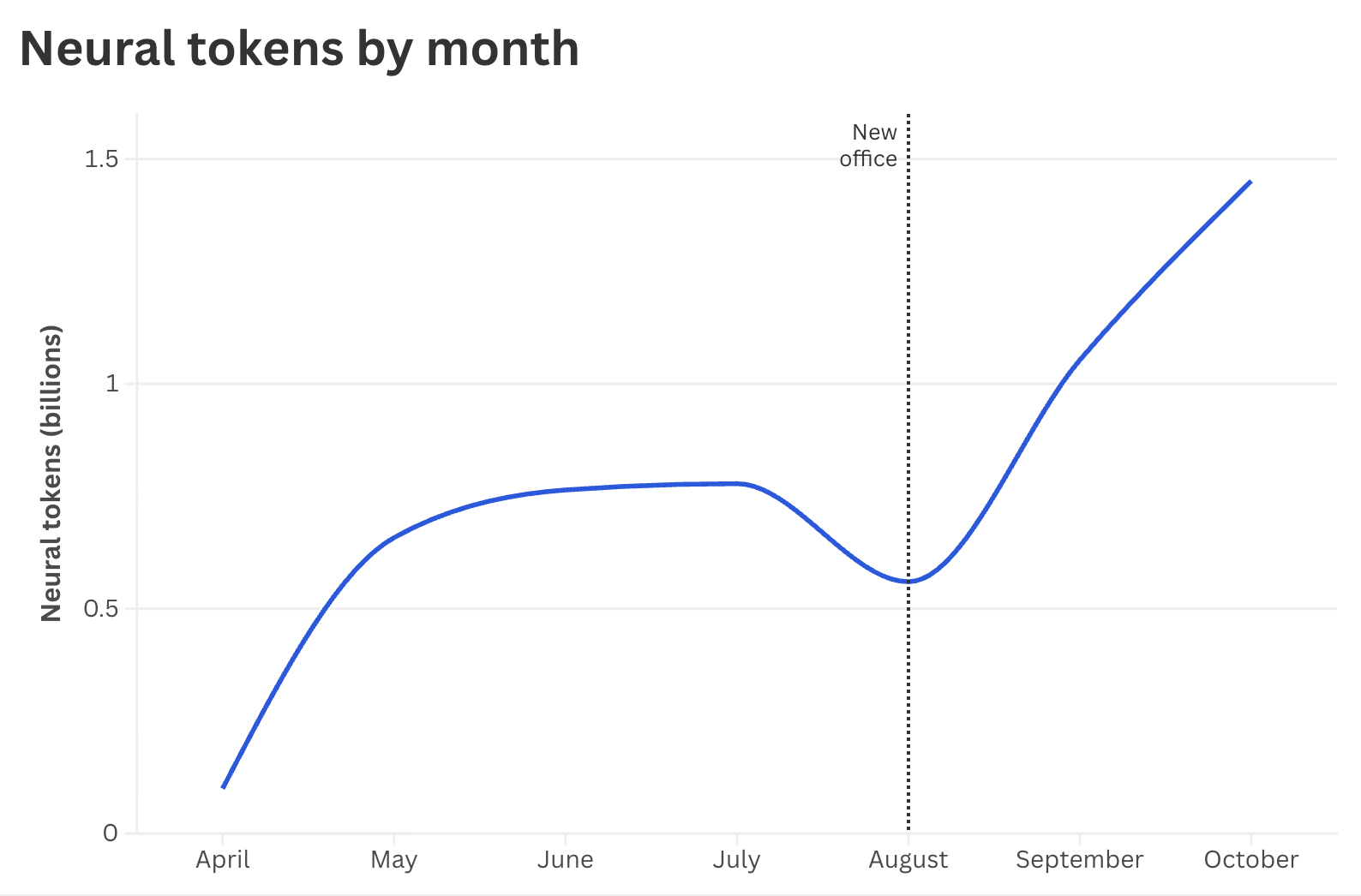
So we got thousands of people to come wear headsets in our basement. This post is about how we collected our dataset—what participants do, the hardware and software involved, and what we learned about operations and ML when we scaled it up.
A participant comes in, signs a consent form, and sits down in a booth. A session manager fits a headset onto them and starts the session. Then, the participant has a freeform conversation with an LLM for two hours.
Sessions vary. Some are listening and speaking with an LLM, and some are reading and typing.[3]We use Deepgram for audio transcription, OSS120B on Cerebras for the LLM responses, and ElevenLabs for voicing certain replies. In the past, we used various Gemma and Llama models on Groq. The goal is to maximize the amount that subjects type or say during the two-hour period, without constraining the topics they discuss.[4]In the beginning, we included tasks like 'retype this sentence', or 'paraphrase this but use this different tone'. Over time, we eliminated these and replaced them with more freeform conversation. We still include a few baseline tasks for calibration and easy model evals. Each session produces multimodal neural data time-aligned with text and audio.
Participants have to touch-type without looking at the keyboard. In the beginning, participants would occasionally press a crazy key combination that crashed or closed the software. We could have fixed this in the code, but that would've taken time—so instead we 'simplified' the keyboards.

What your participants type—and whether it's remotely coherent—is a more difficult problem. We implemented a token quantity/quality scoring system that determines if we invite a participant back for future sessions, and we make sure participants know about this so they're incentivized to engage.
Below are passages typed by participants in May vs. October:
| May: | October: |
|---|---|
| SO, AI NEEDS THIS CODE: 1, THOSE WHO BELONG TO THE CHURCH CAN NEVER BE FOUND GUILTY WHEN SINNED 2. HIDE THE SINS! CRIMES! WHICH IS A FEDERAL CRIME BUT THOSE ARE THE OLDEST TEACHINGS OR LAWS OF CHRISTIANITY! AND WE ARE ALL LIVING IN THIS HELL IN THE WEST. CHRISTIANS ARE DEEMED CRIMINALLY INSANE, PER A JEWISH THERAPIST, AND THE TEACHINGS ARE SUGGEST VERY GROTESQUE CRIMES AND SHE SHOWED ME THE PASSAGES IN THE FAKE VATICAN BIBLE. NO WONDER IS WAS NOT WRITTEN BY JESUS! DUH! | I guess the way I am thinking about it is that since the amygdala is the irrational fight or flight part of the brain it would activate/be used with a higher frequency when a human being finds themselves under threat. Humans tend not to find themselves under threat when experiencing loving and therefore safe interactions. Therefore,when engaging in positive social interaction, the amygdala is less reactive. I don't know exactly what has sparked this interest other than a curiosity to understant the human brain and how we make decisions and funtion as social beings. I guess it all could stem from my interest in improving well being/ reducing suffering. |
| l''''''''''''''''''''''''''''xcccccccccccccccccccccccccccccccccccccccccccczzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzccccckkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkllllllllllllllllllllllllllllllllllllllll,llll | I would travel to local elementary schools and teach kids how to ride bikes as well as teach them bike safety stuff. That was the most enjoyable part and stuck with me the most. I think it was seeing their excitement when they would get riding on their own. And watching their independence and confidence flourish. It was a super rewarding experience. This is so funny, it feels like a job interview. I think its the beginning of a newfound independence and selfhood for a lot of the kids.They get to move on their own accord and get to experience the world in a new way, its the first taste of freedom. |
You'll also get much better engagement if the LLM personalizes the sessions. For the first few months of data collection, participants chatted with the LLM about generic, banal topics. Now, participants introduce themselves to the LLM very early in the session, and the LLM uses that context to tailor back-and-forth conversation to the particular person it's talking to. As a result, participants engage more with the LLM—and therefore provide better data.

Participants often raised discomfort as a distraction from the sessions. Ventilation was a common complaint. So, we bought these fans and these pipes. These can't be plugged in next to the data collection booths (because of electrical interference), so we snake an ~8m ventilation pipe along the ceiling from a central hub into each booth.
Making the headsets comfortable to wear is difficult, since you need to press a 4-pound helmet into participants' scalps. To address this, we cut polygonal sections of padding that compress inwards so as to not cover any sensors.
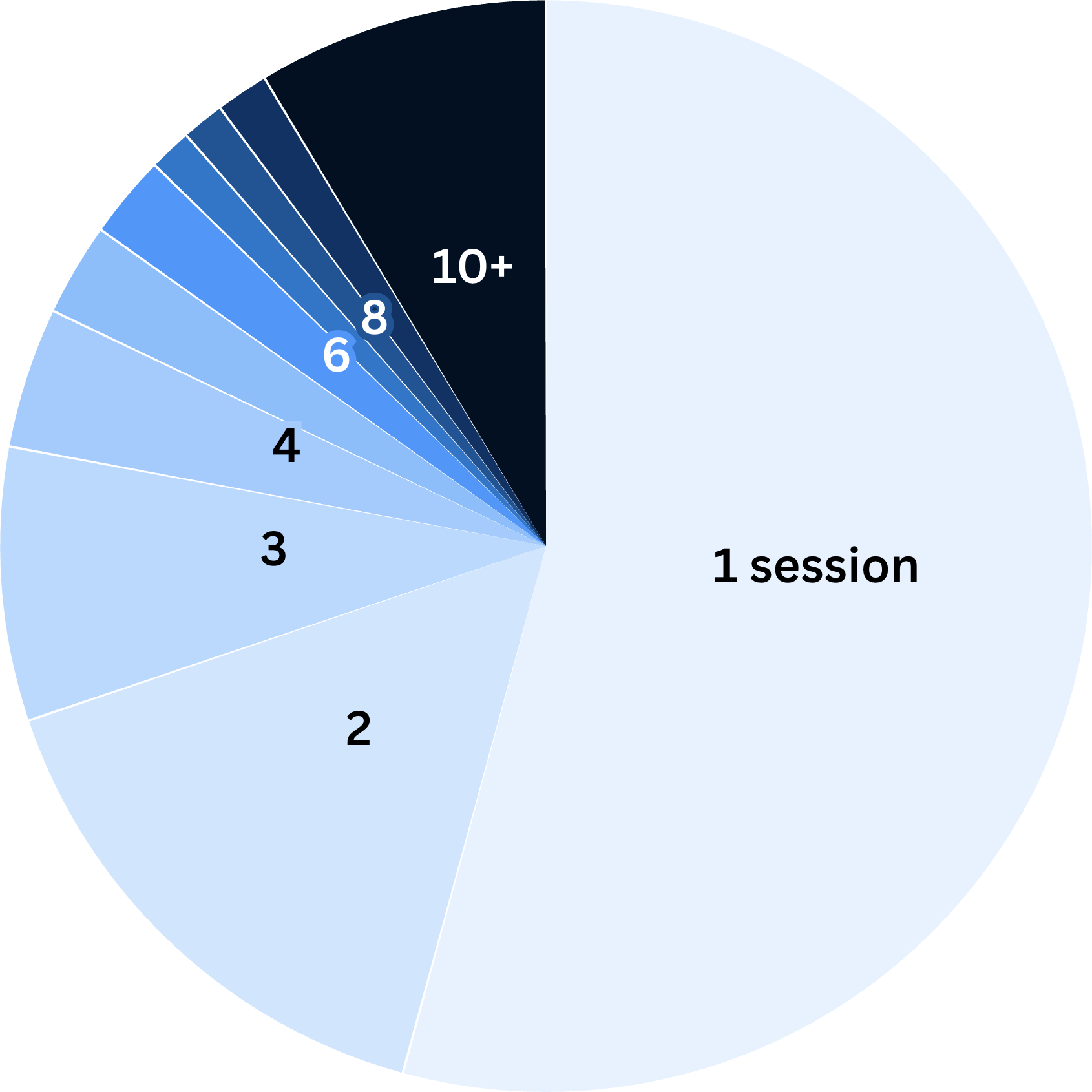
% of participants by # of sessions completed
At first, <20% of participants even finished their first session. Now, >97% complete their first session, and almost half sign up for more.
There were two main things we thought about when we designed the headsets. The first was what modalities the headsets should have, and the second was how training headsets should compare to inference ones.
There are many ways of measuring brain data: common modalities include EEG, fMRI, fNIRS, transcranial ultrasound, and MEG. We tried various modalities, but the main takeaway we found is that you need multiple. You can't practically make it work with just one, even if you get the best possible headset of that modality.
None of the available multimodal headsets were good enough (far worse than the best single modality versions of each). So we bought some of the best single-modality headsets, took them apart, 3D printed parts to make them fit together, and combined them into our own optimized multimodal headsets.[5]We have a 3D printer at our office that we use for prototyping and designing pieces. For the ones we put in production in data collection, we send them out to a professional printer and have them printed in bulk. We usually have them printed in Pa-F Nylon, which is stiffer and holds up longer before needing replacement.
If you want your model to perform well across various neural modalities and across sensors from different providers, you should design and train on a range of headsets. We buy sensors from several providers, combine them into different multimodal headsets, and then use those headsets essentially interchangeably. We also designed our data format such that data from many kinds of sensors fit nicely into a single, standard framework that our model can parse.
Designing headsets for training is very different from designing headsets for inference—what we'll eventually sell as a product. Training headsets should be maximally sensor-dense, can afford to be expensive, and don't need to be as comfortable. In inference, though, few people are willing to wear a 4-pound helmet as they go about their day—even if it can read their minds. So, we did ablation studies. The take-away here is that you should only think about the inference headset once you've trained a model on your data, because that lets you figure out the exact minimal inference headset.

(inference headset concept)

(training headset concept)
What should be shared across both training and inference is your data format. Initially, we got this wrong: we used HDF5 for data collection and storage and processed it into MDS for model training. Eventually, we switched to using Zarr 3 for everything. Zarr 3 gives us chunked, cloud-native storage with the same format for training and inference.
You might think a crucial consideration for training (and for inference) is noise. At first, so did we.
The sources of noise you'll notice are very different depending on which modality you use. That said, all modalities of noninvasive neural data are noisy. We're not disclosing all the modalities or headset configurations we use here, but we'll use EEG as an example. The important lessons, which apply to any modality, are that (1) noise-reduction is only worth it if it doesn't cripple the amount of data you can collect, and (2) you should always keep in mind the logistics of running sessions and recruiting participants.
The classic wisdom is that gel makes EEG data much better, and without it, your data will be substantially noisier. But if you care about data quantity, you probably shouldn't use gel.
It takes up to 30 minutes to apply, and we allocate ~3 minutes for the time between one participant finishing a session and the next one starting.[6]Most kinds of gel also dry out over time, meaning that we likely would've had to make sessions shorter—and fewer participants would have signed up if they had to let us put gel in their hair. Using gel would've >2xed the marginal cost of an hour of data.
Instead, we got the highest quality dry electrodes we could, and we spring-loaded the 3D printed pieces so that a spring presses the electrode against the head. We had to try various strengths of spring because we wanted to maximize contact without causing discomfort. Generally, stronger springs work well at the front and back of the head; and weaker ones on the top of the head and above the ears.
The essential take-away here is that the fast switching time (2-3 mins) is super important. If you care about data quantity, you should operate with some fixed switching time as a constraint, and limit yourself only to interventions that improve quality without violating that constraint.
Most buildings have a lot of background electrical noise, which shows up on any EEG power spectrum—in particular, a spike at 60Hz, the U.S. power line frequency. Here is what that spike looks like with no filtering:
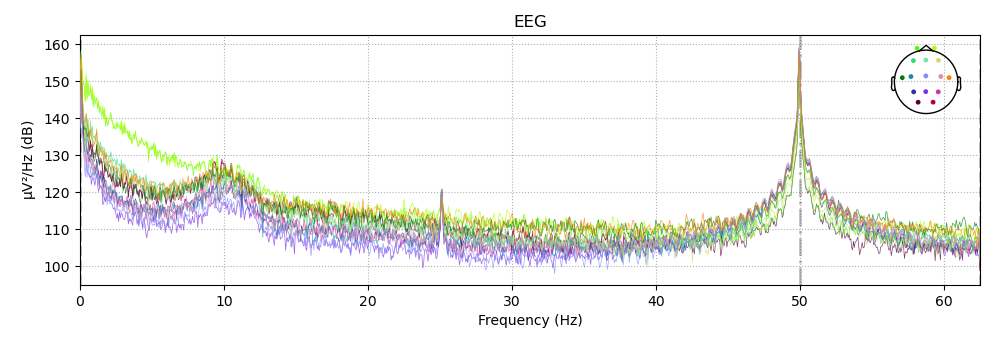
(not from our dataset—example from MNE.[7]Worth noting that this data is from outside of the United States, where the power line frequency is 50hz rather than 60hz.)
At first, we tried to get around this by triple-layering rubber mats around the equipment. But the fundamental issue was that some of the headset components weren't wireless, so we had to plug them into the wall (meaning that the rubber didn't help that much, though it does help a bit and we still use it).
We then tried getting adapters that plug into the wall and output clean power. This didn't really help. Eventually, we used Anker batteries and only plugged stuff into the DC adapters (we got extra batteries so we could switch them out to charge). This helped a lot, but the thing that really helped was turning off all the power to that side of the building.
Turning the power off had a lot of downsides. It meant we had to drag ~30 lb batteries back and forth an average of once an hour to charge, and it was difficult to power some of the headsets with only DC power, which made us drop ~10% of frames.
Luckily, after a few thousand hours, noise stopped mattering as much.
The key observation: data quantity swamps every noise-reduction technique once you cross ~4k-5k hours.
When we only had a few hundred hours, denoising was mandatory. Every extra source of variation—different booths, power setups, posture changes—meant the same neural pattern showed up in fewer comparable examples, so the encoder had less to learn from. Keeping the environment stable and electrically boring was the easiest way to keep the problem manageable.
At ~4-5 thousand hours, that constraint changes. The model now sees the same patterns across many people and setups, and has enough capacity to represent both the mess and the neural signal.[8]Similar effects appear in other modalities. Speech models like Whisper, trained on hundreds of thousands of hours of diverse, weakly supervised web audio, show that trading label quality for sheer quantity improves robustness and generalization (see here). Video-language models trained on uncurated instructional videos learn strong representations even though a large fraction of clip-caption pairs are misaligned or noisy (see here). In each of these cases, once the dataset is sufficiently large and diverse, total volume of data outweighs strict curation and noiselessness for downstream robustness. The decoder gets enough examples to tell apart "this changes with the text" from "this is just the room". At that point, data quantity overwhelms noise, and most of the extreme noise-reduction work stops buying much—so we turned the power back on.
After a few thousand hours, noise stops being the thing to worry about in data collection. The things that matter most are
Since we run sessions 20 hours/day, 7 days/week, we get a lot of bookings and see a lot of people. An Uber driver once started telling us about 'this great new way to earn money in SF'—and it turned out to be our data collection.
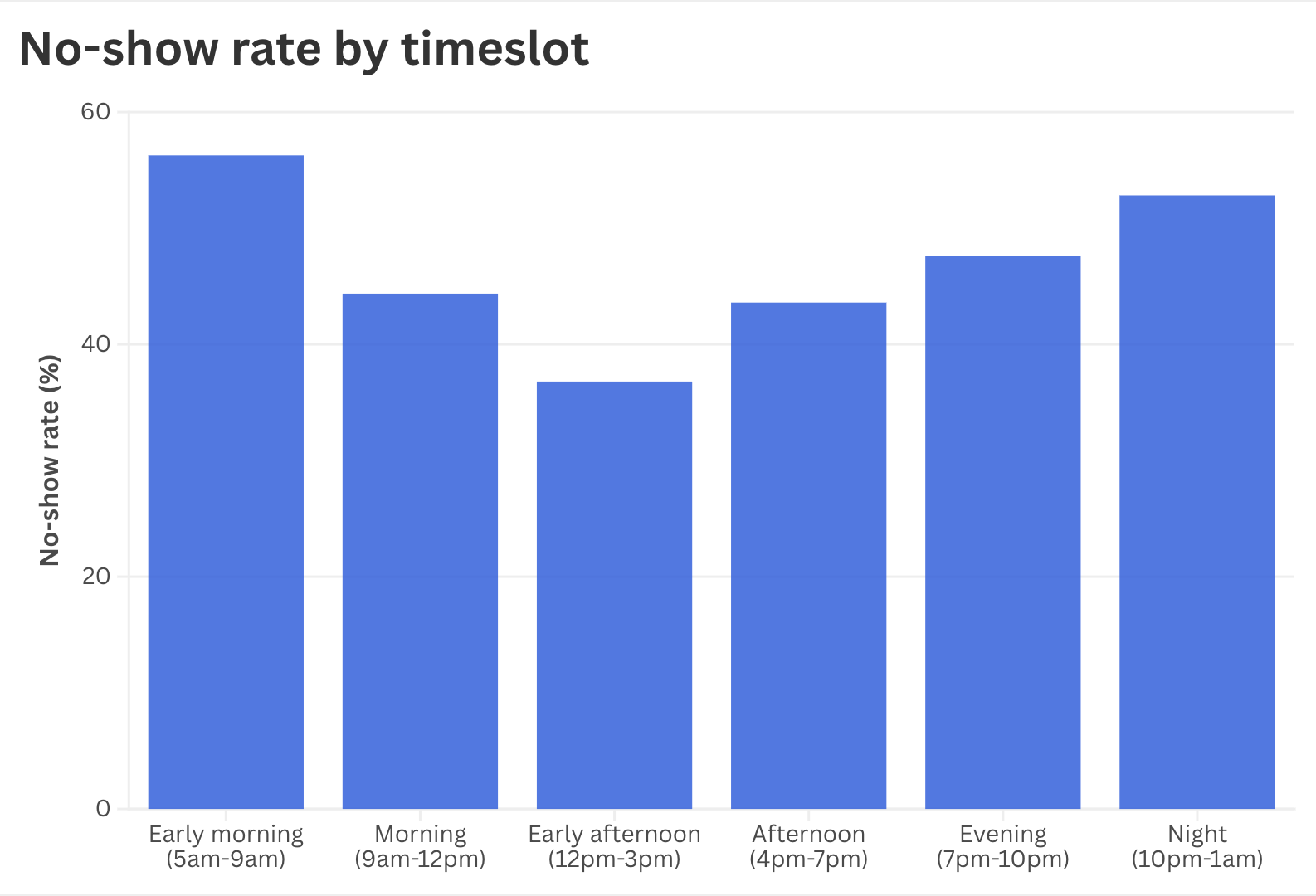
Surprisingly central to getting headset occupancy high enough was building a custom booking suite.[9]We tried Calendly, You Can Book Me, and various other things before making our own. In the end, all the available booking systems had different issues, e.g. not allowing us to blacklist certain people, not allowing dynamic pricing or overbooking, and limited visibility for participants and bookings. There are two main tenets: dynamic pricing and dynamic overbooking. Because few people book at 7am on a Sunday, dynamic pricing means participants are paid more for that slot. Because many people book at 7pm on a Friday, but few of them actually show up, dynamic overbooking allows more people to sign up. The overbooking algorithm can also access information about particular participants.[10]E.g. if Alice has reliably shown up for sessions before, the algorithm lowers the expected total no-show rate during future times when Alice has booked.
In order to get your model to generalize, it's important to get a dataset of thousands of unique individuals. That is *not* just thousands of hours from dozens or hundreds of individuals. In an ideal world, most participants would only come in for one or two sessions, but that trades off hard against total hours. We cap the number of sessions that any one participant is allowed to do at 10 sessions. Before we introduced the cap, our schedule was fantastically full, but we weren't getting enough unique participants because long-term returners were filling all the slots.
Even so, participant recruitment gets easier with scale. We now have participant-ambassadors, whom we pay to recruit more participants for us even after they've completed their 10 sessions.[11]Since the start, we've tried dozens of ways to directly recruit first-time participants. By far the most effective has been Craigslist. Almost every day since April, we've posted a listing—in sections from 'computer' to 'creative' to 'labor gigs'—that advertises a $50 payout for wearing a helmet and typing for two hours.
Between May and October, we cut the marginal cost per usable hour of data by ~40%. Here are the highest-impact things we did.
In August, we entirely rewrote the data format and data collection backend to catch issues in the data live, before participants complete two potentially useless hours of data collection. The sessions stream to the cloud, and we automatically sanity-check each session in real time for modality dropout, token quality, timestamp drift, and alignment jitter. Any session that falls outside the tolerance bands gets flagged for session managers to restart or debug.[12]This is only possible because we changed our data format to use Zarr 3 and optimized it for fast quality checks.
This change alone cut the marginal cost of data by ~30% and ~1.5xed the amount of usable data we collect.
Second, we enable session managers to run more sessions in parallel without sacrificing supervision. We put EVERSECU cameras in the booths, so session managers can monitor and speak directly to participants without leaving the main supervision station. We also made a unified booking -> intake -> data collection backend, which massively simplifies the participant intake process and improves security.[13]As one example of how the unified system helps, it detects how much support a given participant is likely to need (based on, e.g., whether they've attended sessions before, their answers to questions on the booking form, etc.) and how many concurrent bookings are already scheduled for that participant's sign-up time. If needed, it can also stagger booking start-times by 5-10 minutes so session managers don't struggle with an onslaught of arrivals all at once.
The steps to building thought-to-text have always been clear: (1) collect a dataset; (2) train a model; (3) close the loop. We're now well into step two—we spend >95% of our time training models and very little time actively thinking about data collection.
But you can't have a model without a dataset, so you do need to get this part right.
If you're collecting a similar kind of data, training multi-modal models, or want to give us cheap GPUs, we'd love to hear from you. Please reach out to us at contact@condu.it.
And if this dataset sounds cool to you and you want to train models with it, we're hiring engineers and researchers. Reach out to us at jobs@condu.it.
We started out putting each participant in a separate room at a normal work station. We saw huge noise spikes in the data from participants moving their heads, and sometimes they'd get up and walk around with the headset on or take the headset off without telling us.
The solution to this was putting multiple booths in one shared room for easier supervision. We also installed chinrests that hold participants' heads still, which help reduce motion artifacts in the data.[14]We initially wanted to get something like an optician's chinrest, but the bar across the forehead got in the way of the headset. We ended up buying speaker stands and sawing pieces of wood to screw onto them. This works pretty well, although participants don't always use them. You should ensure that any desks, chairs, and chinrests that you buy are height-adjustable.
Now, we use these nice phone booths (~$10k each, though you can sometimes get them used). We initially picked them because they were the best option for turning into safe Faraday Cages.
We've stopped worrying so much about electrical noise, so we only ever bothered turning one booth into a Faraday Cage. But professional phone booths save a lot of hassle and set participants at ease, so you should use them if you can.
If you don't have two weeks to wait for booths to arrive or if you want a cheaper option, we also used these vocal recording booths. The downside of using these is that they aren't remotely soundproof, so the participants could hear each other talking—which interfered with speaking and listening tasks.
We added three layers of soundproof curtains.[15]This still wasn't enough, so we got dozens of sound panels and used rope to hang them wall to wall in the booths. Unfortunately, the weight of the curtains caused the booths to collapse. The solution to this is a lot of rope, which we used to tie the poles of the booth together and then nailed into a hook in the wall.



(our first DIY booths, soundproofed) (stock vocal booths) (our Zenbooth booth)
It costs ~$2,000 to set up these booths: $600 for the booth itself, $1,300 for soundproofing, and $100 for miscellaneous construction (rope, screws, etc). They look less professional, and you can't make them into a safe Faraday Cage, but otherwise this setup actually does work pretty well. We have a couple that we still use in our current data collection center, and they've been running flawlessly 20 hours/day for months.
Copyright © Conduit 2026